Thank you for this valuable forum and for all the hard work you do.
I'm working on a DMA driver which streams data via PCIe to a memory buffer which my driver needs to process fast enough before it gets overridden.
Here's the main design:
ISR()
{
TraceLoggingWrite(DMADriverTraceProvider, "ISR started");
status = WdfDpcEnqueue(...);
if (FALSE == status)
{
//DPC already in Queue
TraceLoggingWrite(DMADriverTraceProvider, "DpcEnququeFailed");
}
TraceLoggingWrite(DMADriverTraceProvider, "ISR ended");
}
Normally I have a corresponding DPC for each ISR, but in this case the ISR pushes the DPC job into the framework queue successfully, but for some reason the framework won't pop the job from the queue for very long (124[msec]) so DPC doesn't run and my buffer gets corrupted.
Here are my questions:
What could possibly cause the WDF to ignore the DPC job in the queue?
What is the right approach of debugging such a tricky and rare behavior in production:
a. Should I run WPR in the background? Files are very big - how can I synchronize WPR with the actual event I'm interested in and to store only the WPR output at the very moment of the fault?
b. Is there a way to see windows internal trace events such as context-switches, other ISRs/DPCs kicking in and starving my DPC?
How can I tell why is my DPC delayed and what does the framework do while I expect my DPC to run?
Your dpc is being 'ignored' because another dpc is running on the cpu your dpc is queued to. There is very little you can do about the latency from other interrupt activity. The little you can do is basically to not assume a 1;1 correspondence between interrupt events and dpc execution, and if this is a purpose built dedicated system where you control the hardware configuration, isolating your isr/dpc to its own cpu, based on an analysis of which cpus are being used for other interrupt activity.
One other consideration is to consider if a polling based approach would work better.
I agree with everything Mr. @Mark_Roddy wrote above.
Key in what he wrote is: You cannot assume that calls to WdfInterruptQueueDpcForIsr (or, WdfDpcEnqueue... why are you calling that particular function, by the way??) and DPC invocations are 1:1 -- that's not how Windows is designed to work. In your DPC, you need to (try to) do any service that your device requires (for that type of DPC, if you have multiple interrupts/messages and you queue different DPCs for each).
If you have an assumption today that one request to queue your DPC object will get you one call to your DPC, changing your code to NOT have that assumption is your first task. THEN perhaps you won't see the latency that you're seeing now.
AFTER removing that assumption, we can talk further about the OTHER very valid things that Mr. Roddy said.
One key to making a design like this work is to make sure your DPC processes ALL of the outstanding data. Don't attempt to rely on a one-DPC-per-interrupt model. Before your DPC exits, just check for more.
I have done several telemetry products where we eliminated the use of interrupts altogether by monitoring "completion" bits in the packets. Most audio devices work that way -- that's the fundamental benefit of the WaveRT audio model.
I had interrupts arriving while a DPC was being processed. I initially increased the size of the buffer to create longer times in between interrupts however I still missed the odd DPC.
You can NOT "miss the odd DPC" or Windows is broken. DPC Objects are queued in a list for invocation. Each such object has a single forward and backward pointer. It can only be on one list at a time.
If you request to add the DPC Object to the list, and the DPC is already on the list, then your request is satisfied. This is the way Windows works. There is not now, nor has there ever been, any implication that one request for a DPC to be invoked will result in one DPC invocation. Rather, the model is "1 or more requests for a DPC to be invoked will result in one DPC invocation." This is simply how Windows works.
If you request to add the DPC Object to the list, and the DPC Object is NOT on the DPC List (which is the case while the DPC is running), then the DPC Object is placed on the DPC List. So... multiple DPCs can in fact be in progress simultaneously on different processors.
I'm not sure why we're discussing this, or why ring buffers are relevant, or how a DPC can be "missed"...
Your dpc should always execute whatever offloadISR(devExt) does. The point is to perform ALL available work on each dpc invocation (except of course that you cannot execute your dpc for longer than 100ms.)
Doing this work in your ISR is a Real Bad Idea. And as I noted earlier in another message, if you can poll your hardware for available work (i.e. a ringbuffer) then that opens up other options that are not as constrained as the interrupt stacks are.
As the hardware uses a ping pong buffer I can end up losing data which is a worse scenario.
Maybe I diagnosed the problem incorrectly. I used latency monitor software and some drivers (NDIS) appears to use and IRQL of DIRQL for long periods (>25ms) intermittently.
Also we need as short a time in between interrupts so we can perform control routines.
I get it now: I can't rely on DPC running at least once after each DPC enqueue request, then what is considered a good design to my system?
I have a PCIe custom card streaming data into a 64MB ping-pong buffer.
Each half (32MB) is filled up within ~51[msec] so I must guarantee that the DPC will run within ~100[msec] from the ISR at max.
Is this achievable?
How?
I'm already doing this. My data buffer is a 64MB ping-pong buffer and I process all the data in the buffer at each DPC, even if there's more than 32MB, but since the streaming rate is ~51[msec] per half (32MB) I must guarantee that a DPC will run no more than 100[msec] after the ISR.
But let me ask this:
If I already have a DPC request in the framework queue, and the framework is currently running another (someone else's) DPC- shouldn't it go back and pop my DPC when it finishes running the other DPC?
What could cause the framework to pop my DPC and run it?
If I call WdfDpcEnqueue() once again I get FALSE in return which (I assume) means nothing was done, so when will the framework get back to pop my DPC?
The DPC list is kept on a per (logical) processor basis. It's (almost always) FIFO. Your DPC will be dequeued and executed when it's at the head of the DPC list (all the DPCs before it have been processed) and before the processor returns to an IRQL less than IRQL DISPATCH_LEVEL.
I agree!
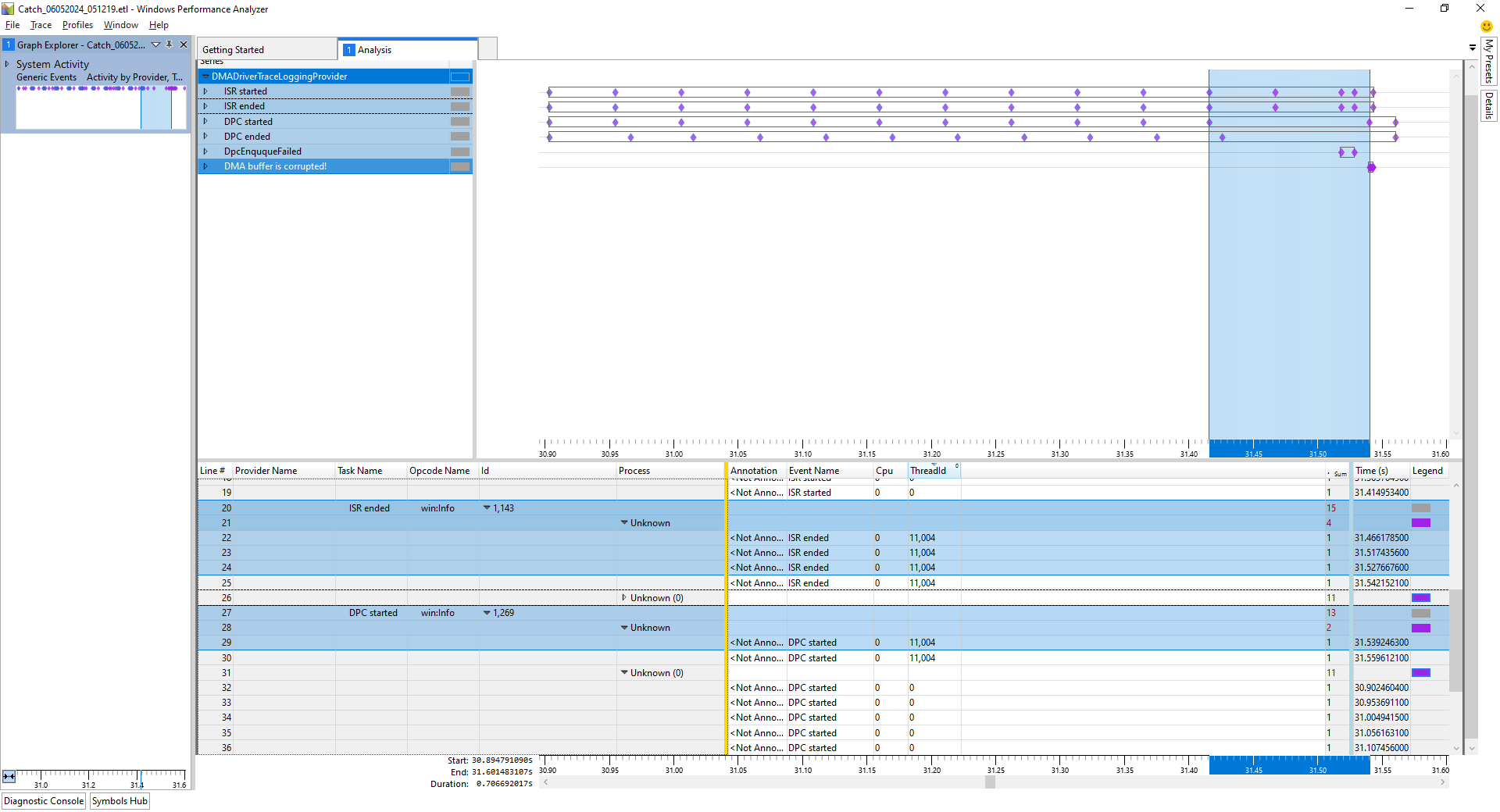
As you can see in the screenshot I attached in my first post, there's 'something' in the system causing my DPC to run 124[msec] (marked blue) after the DPC was enqueued.
How can I see other DPC's in my WPR recording?
What should I do to see what this specific CPU core is doing while not letting my
DPC in?
Yes, I've read it several times but still don't understand why would you say I can't expect each successful DPC enqueue request to result in a DPC run.
If I successfully enqueue a DPC request and the framework must eventually run my DPC (even if other DPC's are already in the queue), then I can assume that each successful call to WdfDpcEnqueue() must result in a DPC run.
What I can't assume is that it will run immediately (<1[msec]) after the ISR, but it will surely run.
Am I wrong?
Thanks for your reply.
I'm trying to rethink my design.
I was sure that an interrupt based solution would be the best approach,
but since I'm losing data I'm willing to consider the polling approach.
If I get it right then you suggest adding a thread to poll for new data in the buffer on a timely basis,
but if my current problem is DPC not running due to 'something' blocking it,
wouldn't the same 'something' block my new thread as well?
since the new thread will have a lower priority than the DPC's.
Then where should I poll for new data in the buffer?
The only entity which won't get blocked by a DPC is ISR, but it's not a good practice to process the buffer in an ISR.
That's an ETERNITY. ISR to DPC latency is typically measured in micro-seconds.
In all sincerity that is not what I found. With my initial hardware it was set up to deal with roughly 4ms (4KB per half ping pong buffer) I kept getting missed buffers (I used the ring buffer to diagnose this).
After moving to 64ms (64KB per half buffer) problem went away by and large until the guy writing the user mode code failed to get read requests to me in a timely fashion. Once this was fixed it runs without missing a DPC.
If you have a choice, a ping pong buffer isn't an ideal design. There is some trade off between the size of the buffer and how often it is served, but in general more smaller buffers that get handled more frequently is a better approach than fewer larger buffers.
using an example from storage (I have no idea what your device does), PIO is terrible, SCSI with command tagged queuing is better, and NVMe is a lot better
I get what you say but I'm afraid I don't understand how this would help:
Let's say I have a 64MB ping-pong buffer which generates an interrupt once every 32MB (~51[msec]) and when I miss it (DPC doesn't within >100[msec] since ISR) then the buffer gets corrupted.
Now how would it help if the ping-pong buffer is modified to be a cyclic buffer generating 4 interrupts (once every 16MB=25[msec])?
I would then get 4 interrupts in 100[msec] but none of them will cause a DPC to run since there's something blocking me for > 100[msec].
Am I wrong?
I would think that the same entity starving my DPC for >100[msec] will now starve 4 DPC's
since if my DPC gets starved for 124[msec], then if I will receive 4 interrupts per