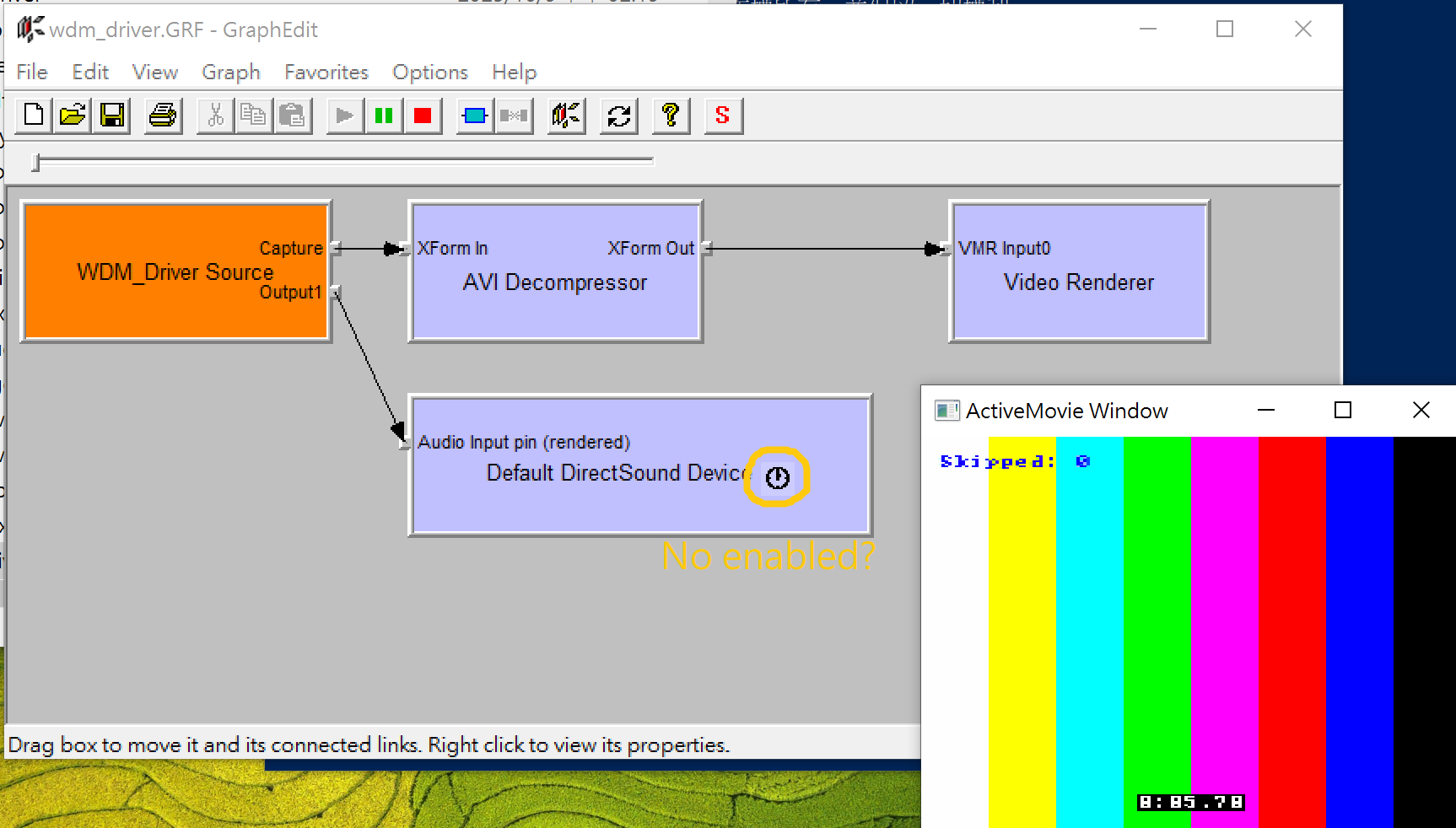
I referred to avssamp and added an audio pin into avshws. Now on graphedit it operates normally but there is no sound output when I play it. Some difference between avshws and avssamp are some advanced audio pin properties, and the clock status when playing. I just suspect that I might not be setting the time of the audio pin correctly. However, I actually have no idea what the real problem is. Could anyone suggest some topics or directions that I should look into?
NTSTATUS
CAudioCapturePin::
AVStrMiniPinProcess( In PKSPIN Pin
)
{
DBG_ENTER("(DeviceState=%d)", m_Pin->DeviceState);
NT_ASSERT(Pin == m_Pin);
// PLIST_ENTRY ListEntry;
PKSSTREAM_POINTER StreamPointer;
PKSSTREAM_HEADER StreamHeader;
PUCHAR DataPointer;
ULONG BytesToProcess;
NTSTATUS Status = STATUS_SUCCESS;
StreamPointer = KsPinGetLeadingEdgeStreamPointer (
Pin,
KSSTREAM_POINTER_STATE_LOCKED
);
while (NT_SUCCESS (Status) && StreamPointer) {
//
// If no data is present in the Leading edge stream pointer, just
// move on to the next frame
//
if ( NULL == StreamPointer -> StreamHeader -> Data ) {
Status = KsStreamPointerAdvance(StreamPointer);
continue;
}
StreamHeader = StreamPointer->StreamHeader;
// refer to video
BytesToProcess = StreamPointer->Offset->Remaining;
DataPointer = (PUCHAR)StreamHeader->Data;
DBG_TRACE("BytesToProcess=%u", BytesToProcess);
if (BytesToProcess > 0) {
ULONG BytesUsed = m_WaveObject -> SynthesizeFixed (
// TimerInterval,
10000000, // 1 sec
(PVOID)DataPointer,
BytesToProcess
);
DBG_TRACE("BytesUsed=%u", BytesUsed);
if (m_Clock){
StreamHeader->PresentationTime.Time = m_Clock->GetTime();
DBG_TRACE("PresentationTime=%I64d", m_Clock->GetTime());
StreamHeader->PresentationTime.Numerator =
StreamHeader->PresentationTime.Denominator = 1;
StreamHeader->OptionsFlags |=
KSSTREAM_HEADER_OPTIONSF_TIMEVALID;
}
}
Status = KsStreamPointerAdvance(StreamPointer);
if (Status != STATUS_SUCCESS) {
break;
}
} // end while (TRUE)
// refer to video
//
// If we didn't run the leading edge off the end of the queue, unlock it.
//
if (NT_SUCCESS (Status) && StreamPointer) {
KsStreamPointerUnlock (StreamPointer, FALSE);
} else {
//
// DEVICE_NOT_READY indicates that the advancement ran off the end
// of the queue. We couldn't lock the leading edge.
//
if (Status == STATUS_DEVICE_NOT_READY) Status = STATUS_SUCCESS;
}
//
// If we failed with something that requires pending, set the pending I/O
// flag so we know we need to start it again in a completion DPC.
//
if (!NT_SUCCESS (Status) || Status == STATUS_PENDING) {
m_PendIo = TRUE;
}
DBG_LEAVE("()=0x%08X", Status);
return Status;
Why did you choose to do it this way, instead of just starting from avssamp? WIth avshws, you have two unrelated pins.
You’re telling SynthesizeFixed to advance the syntheses one full second each time, even though the buffers you’ll be getting for audio are quite small. Have you done debugging to see how large your audio buffers are?
My next task is to develop a video capture card driver. The data source comes from hardware, and the pin-centric/avshws seems to be the suitable sample. However, avshws only demonstrates the video part, while my work needs to handle both video and audio.
Passing one second to SynthesizeFixed is just a temporary approach. I modified its internal logic so that it copies audio data based on BytesToProcess and recalculates the time progression accordingly. Please refer to the attached log.
The reason I implemented it this way is that I have no clear idea how much audio data should be filled for each StreamPointer. You mentioned that this is because the two pins are unrelated, so regarding synchronization between the two pins, which topic should I study further? (The data source will be HDMI, which includes both video and audio.) Thanks in advance for any suggestions.
The following is a section of windbg log. CCapturePin is the video pin of avshws. CBasePin is the original CCapturePin of avssamp, it is inherited by video and audio pin class in avssamp. CAudioCapturePin is the audio pin from avssamp. The audio format is 44.1 KHz, 24 bit, stereo.
If this is coming from a device capturing audio and video together, like a camera with microphone, then you WANT the two pins to be related. You want a filter-centric driver, where all the pins get filled together. That’s the only way to achieve lip sync.
I have no clear idea how much audio data should be filled for each StreamPointer
You’re simulating hardware here. If 16ms have elapsed since the last send, then you send 16ms worth of audio data. In your case, with 264,600 bytes per second, that would be 4,233 bytes.
You want a filter-centric driver, where all the pins get filled together. That’s the only way to achieve lip sync.
That’s really valuable information! Thanks a lot!
When processing video, I just need to fill the data for each frame. But for audio, I’m not sure if there’s a similar concept of a “frame”. So does that mean I should precisely calculate the elapsed time and then fill in the correct amount of data accordingly?
In my current practice, I just want to play back the entire audio file correctly. Can I simply fill the buffer sequentially with the full audio content without worrying about the elapsed time?
Sorry for asking so many questions — should I read any specific topics in the Hardware Developer Documentation to better understand this part?
Technically, a “frame” in the audio sense is one sample – 6 bytes for you. You just need to fill the buffers with whatever data you have. I thought the avssamp sample used the elapsed time to decide how much data to produce. The clock in your graphedt image means that the audio pin has been selected as the “master clock” for the graph, because audio tends to be continuous and well-regulated.
I originally thought the issue was related to synchronization or clock settings. But after your reminder that I just need to properly fill the buffer, I focused on checking the values of StreamHeader. In the end, I found that DataUsed wasn’t being set, because in video pin, it didn't do it in the process routine but is deferred to CompleteMappings.