Mr. @Don_Burn raised a question in my mind about the number of I/O Requests per second on can push through a KMDF driver, using one thread doing synchronous I/O.
I decided to do a very quick and simple test. Here’s my code:
constexpr auto READ_BUFFER_SIZE = 4096;
void
SendIOs();
void
CountIOs();
UCHAR _ReadBuffer[READ_BUFFER_SIZE];
HANDLE _DeviceHandle;
volatile ULONGLONG _CompletedRequests;
constexpr auto MS_BETWEEN_CHECKS = 5'000;
ULONGLONG _OpsLastPeriod = 0;
BOOL
WINAPI ConsoleHandler(DWORD signal) {
if (signal == CTRL_C_EVENT) {
printf("^C Exits:\n");
ExitProcess(1);
}
return(true);
}
int main()
{
ULONG code;
if (!SetConsoleCtrlHandler(ConsoleHandler, TRUE)) {
printf("\nERROR: Could not set control handler");
exit(0);
}
//
// Open the nothing device by name
//
_DeviceHandle = CreateFile(L"\\\\.\\NOTHING",
// _DeviceHandle = CreateFile(L"F:\\_work\\x.txt",
GENERIC_READ | GENERIC_WRITE,
0,
nullptr,
OPEN_EXISTING,
0,
nullptr);
if (_DeviceHandle == INVALID_HANDLE_VALUE) {
code = GetLastError();
printf("CreateFile failed with error 0x%lx\n",
code);
return (code);
}
std::thread SendThread(SendIOs);
std::thread CountThread(CountIOs);
SendThread.join();
CountThread.join();
ExitProcess(0);
}
void
CountIOs()
{
using timer = std::chrono::high_resolution_clock;
timer::time_point clock_start;
timer::time_point clock_end;
timer::duration elapsed_time;
std::chrono::milliseconds elapsed_ms;
while(TRUE) {
Sleep(MS_BETWEEN_CHECKS);
clock_end = timer::now();
elapsed_time = clock_end - clock_start;
clock_start = timer::now();
elapsed_ms = std::chrono::duration_cast<std::chrono::milliseconds>(elapsed_time);
printf("Total IOs: %llu\n", _CompletedRequests);
printf("IOs last period: %llu\n", _CompletedRequests-_OpsLastPeriod);
printf("IOs/Second: %lu\n", (ULONG)( (_CompletedRequests-_OpsLastPeriod) / (elapsed_ms.count()/1000)));
_OpsLastPeriod = _CompletedRequests;
}
return;
}
void
SendIOs()
{
DWORD bytesRead;
DWORD code;
while(true) {
//
// Send a read
//
if (!ReadFile(_DeviceHandle,
_ReadBuffer,
sizeof(_ReadBuffer),
&bytesRead,
nullptr)) {
code = GetLastError();
printf("ReadFile failed with error 0x%lx\n",
code);
ExitProcess(code);
}
_CompletedRequests++;
} // while TRUE
return;
}
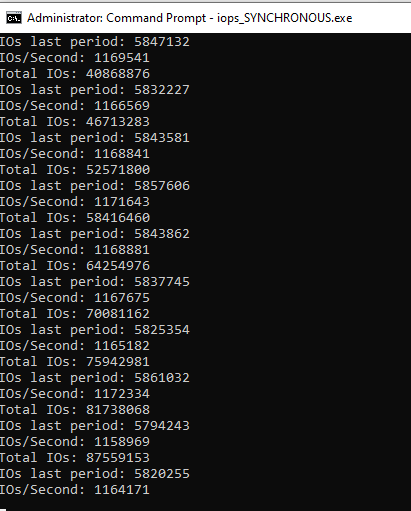
Using the code above, sending 4K reads, and using the NOTHING_KMDF driver that we use in our WDF Seminar from GitHub (which uses SEQUENTIAL dispatching and completes every read with success and zero bytes)… I~~ get 310K I/Os per second. If I make the buffer size on the read zero (and DO NOT change the Queuing to allow zero-length Requests) I get about 410K I/Os per second. This last number pretty much represents just the time through the I/O Manager and the Framework (in and out), as the driver never gets called.~~ (see below for an update)
If I change the dispatching to Parallel there’s no significant change in the throughput (strangely, it seems like it’s a tiny bit lower if anything).
While this is higher than Mr. Burn reported, this is significantly lower than I expected.
The test hardware was an Intel Core i7-9850HE CPU @ 2.70GHz – The system was connected to the Internet during the tests, has some custom hardware installed (but not active), but was otherwise stock Windows 10 Pro 20H2 (19042.1466).
If I have the time, I’ll run some more tests with some more sophisticated user-mode schemes. But no guarantees.
I’d be very curious if other folks are able to repeat these numbers – or provide a critique of my test code above.
Peter